

Understanding Autoencoders
TheGuestBites #2 - Daniel - Compress, Clean, and Discover Patterns with Neural Networks


We’re kicking things off with Daniel García, machine learning educator and creator of The Learning Curve. In this issue, Daniel dives into the world of autoencoders — a neural network technique that goes far beyond just copying data.
Through real-world demos and crisp explanations, he reveals how autoencoders help us compress complex data, clean up noisy signals, detect anomalies, and even generate new content. Whether you're curious about smarter data workflows or the magic behind generative models, this breakdown makes a foundational concept feel both approachable and powerful.
— Josep

Hi! I’m Daniel García, the tinkerer behind The Learning Curve, where I break down machine learning concepts into real-world demos and practical insights for anyone curious about AI.
In this issue, we’ll explore a tool that’s both powerful and deceptively simple: autoencoders.
While they’re often introduced as models that “just copy their input,” the truth is much richer.
By learning to compress and reconstruct data, autoencoders unlock everything from smarter data cleaning to generative art. If you’ve ever wondered how machines learn to see structure in chaos, this one’s for you.
What is an Autoencoder?
An autoencoder is a type of neural network designed to take in data, compress it, and then reconstruct it as closely as possible to the original. But it’s not just copying — the key feature is a bottleneck, a deliberately small hidden layer that limits how much information the model can store.
This constraint forces the model to learn the most important features of the input data. It must filter out noise, redundancy, and irrelevant detail in order to create a useful summary — called the latent representation.
Once trained, autoencoders can be used for compression, denoising, anomaly detection, and — in some variants — even creative generation of new data.
1. Why Should You Care?
Let’s take a closer look at how autoencoders show up in the real world and why they’re worth adding to your machine learning toolbox.
1.1 Compression (Dimensionality Reduction)
Autoencoders are one of the most flexible tools for dimensionality reduction. When working with high-dimensional data like images, sensor arrays, or audio signals, storing or processing that data in full can be expensive. Autoencoders solve this by learning a more compact version.
Instead of manually engineering features, the network automatically learns a compressed form that keeps the structure but discards unnecessary detail. This is especially useful for speeding up downstream models or visualizing data in two or three dimensions.

1.2 Denoising (Data Cleaning)
A common real-world problem is noisy data. Whether you’re scanning documents, recording audio, or collecting signals from sensors, the data you get is rarely clean.
A denoising autoencoder solves this by training the model to take in noisy input and predict the clean version. This forces the network to ignore irrelevant variations and reconstruct only the core signal.
It’s a data-driven way to clean inputs without needing to handcraft filtering rules. If you’re dealing with messy datasets, this can make a huge difference in performance downstream.

1.3 Anomaly Detection
Autoencoders are also a powerful tool for spotting things that don’t belong. By training a model on normal data — for example, regular sensor readings or typical user behavior — it becomes very good at reconstructing those patterns.
But when an unusual input comes along, the autoencoder struggles. Its reconstruction will be poor, and the reconstruction error will spike. That spike is a useful signal: something about this input is different from the norm.
This technique is widely used in fraud detection, predictive maintenance, cybersecurity, and monitoring for system failures.

1.4 Generating New Samples
Not all autoencoders are just for cleaning or compressing data. Some are built to generate new data entirely.
Variational Autoencoders (VAEs) treat the latent space as a probability distribution rather than a fixed point. This allows the model to sample new points in that space and decode them into plausible new outputs.
In practice, this enables you to create new images, sounds, or sequences based on the structure learned from training data. It’s one of the most creative and experimental branches of unsupervised learning.
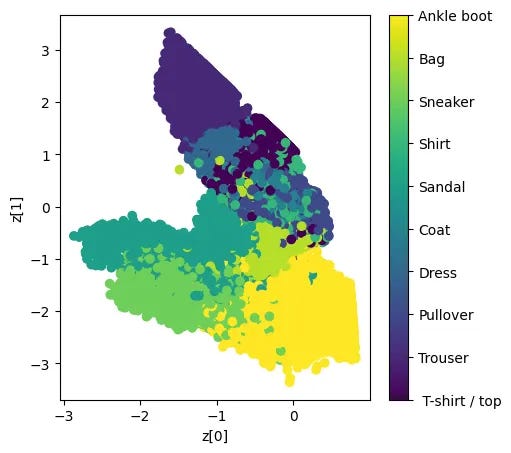
2. How Autoencoders Work
The architecture of an autoencoder is made up of two main parts:
Encoder: This compresses the input data into a smaller internal representation (the latent vector). It’s like summarizing a paragraph into a sentence.
Decoder: This takes that compressed summary and tries to recreate the original data as closely as possible. The goal is to make the output look just like the input.
The model is trained by minimizing a reconstruction loss, a measure of how different the output is from the original. This could be mean squared error (for continuous data like images) or binary cross-entropy (for normalized or binary data).
Without the bottleneck, the network would just memorize and copy the data. But with the bottleneck, it is forced to learn patterns and compress meaningfully.
3. Autoencoder Variants
Autoencoders come in many forms. Here’s a quick guide to the most common variants and what they’re useful for:

Let’s dig a little deeper into the more interesting ones:
3.1 Sparse Autoencoders
In this version, we don’t necessarily make the latent space smaller — instead, we encourage the model to activate only a few neurons at a time. This sparsity leads to representations where different neurons specialize in detecting different features.
We add a penalty during training that discourages the model from turning on too many neurons. The result is a more interpretable and often more robust model that can still extract useful features.
3.2 Contractive Autoencoders
These are designed to be resistant to tiny changes in the input. They include a penalty that discourages the model from making big changes in the encoding in response to small changes in the input.
This is useful for tasks where inputs may be noisy or jittery, but we want the model to focus on the stable patterns.
3.3 Variational Autoencoders (VAEs)
VAEs change the way we think about the latent space. Instead of mapping inputs to a single point, they map them to a probability distribution — usually Gaussian. This enables you to sample new points and generate new outputs.
To make this work, VAEs add an extra penalty term that ensures the latent space stays well-behaved (smooth, continuous, and compact). This is what allows them to generate data that looks convincingly real.
4. Three Mini-Projects to Try
Let’s make this practical. Here are three hands-on projects you can try to explore different use cases of autoencoders.
Project 1 – Compression with MNIST
Train a basic autoencoder on MNIST, a dataset of grayscale images of digits. After each training epoch, save a set of reconstructions and compare them to the originals.
You’ll be able to visually track how the model learns to compress and reconstruct the data over time — starting with blurry blobs and ending with recognizable digits.

Project 2 – Audio Denoising
Record yourself saying a short phrase like "machine learning rocks" while there’s background noise (e.g. fan or vacuum cleaner). Alternatively, add artificial Gaussian noise to a clean recording.
Convert the audio into a spectrogram, then train a denoising autoencoder to reconstruct the clean signal. The model will learn to ignore the noise and focus on the speech signal.
Project 3 – Anomaly Detection in Sensor Data
Use a dataset of sensor readings from an industrial process or simulated IoT environment. Train an autoencoder only on normal data. Then introduce some outlier readings (e.g., spikes, drops, or irregular behavior).
Monitor the reconstruction error over time. When it spikes, it’s likely an anomaly. This is a powerful technique for predictive maintenance and safety monitoring.
5. Common Questions About Autoencoders
Is this just fancy PCA?
They’re related — both compress data — but PCA is linear and deterministic. Autoencoders are nonlinear and can be scaled and customized for many more types of input.

How do I pick the latent size?
A good rule of thumb is to start with log base 2 of your input size. From there, adjust based on how well the model reconstructs data and whether it generalizes well.Why are my reconstructions blurry or inaccurate?
Check your latent size, your loss function, and whether your train/test split is correct. Blurry outputs often mean your model doesn’t have enough capacity or hasn’t trained long enough.Can I generate new data with a vanilla autoencoder?
Not reliably. You’ll need a Variational Autoencoder (VAE) or a GAN if you want to generate novel samples.
6. Wrapping Up
Autoencoders are a foundational tool in the machine learning world. While they’re often described as models that "just copy the input," the reality is that they learn how to compress and represent the essence of your data. Once trained, they can do much more than reconstruction — they can clean, compress, detect, and even create.
Over the coming weeks, I’ll be publishing walkthroughs on The Learning Curve showing exactly how to build each of the three mini-projects above, step by step. That means you’ll not only understand the theory — you’ll get working code, visualizations, and practical insights to make it your own.
Daniel is an ML engineer and writer of The Learning Curve, a newsletter that makes AI make sense—no hype, no jargon. He’s been through every stage of academia (yes, all the way to a PhD), worked in startups and consulting, and now shares the kind of lessons he wishes he’d had when he started: clear, practical, and fluff-free.
 | A guest post by
|