

CS8 - The Transformers Architecture 🤖 (Part I)
Demystifying Transformers: A Three-Part Deep Dive into AI’s Most Powerful Architecture

This article aims to kicking off a three-part deep dive into one of the most revolutionary AI architectures of our time:
Transformers.
Here’s what’s coming your way:
✅ Week 1: Understanding the Transformers architecture
✅ Week 2: The Encoder → Link
✅ Week 3: The Decoder → Link
The Transformers Architecture - Part I
With GPT-3.5 gaining 1 million users in a week, it’s clear AI is reshaping our world.
But how do these models actually work?
💡 The magic lies in the Transformer architecture, introduced in Google’s 2017 paper, "Attention is All You Need."
Before starting, here you have the full-resolution cheatsheet 👇🏻

And now… let’s break it down!
1 What is a Transformer?
A transformer model is neural network that excels at understanding the context of sequential data and generating new data from it. Initially developed for machine translation, it has evolved to become the backbone of nearly all modern AI models.
The key innovation?
Unlike traditional models that process words sequentially (like RNNs), Transformers process entire sequences at once using self-attention without using recurrence, allowing them to focus on relevant parts of the input sequence and understand the dependencies between them.

2 What is the Transformer Architecture?
Transformers convert natural language input into natural language output without relying on RNNs or convolutions.
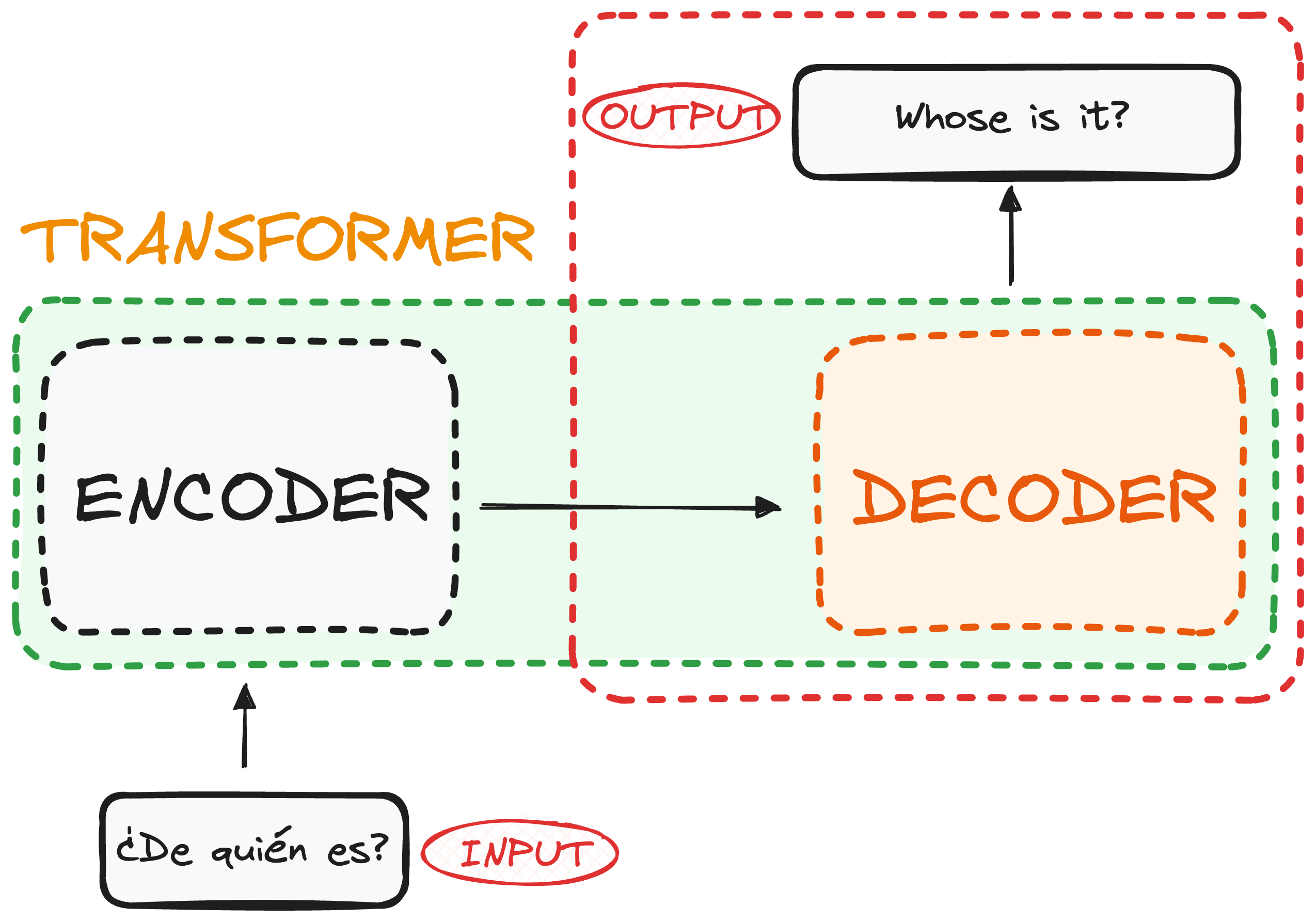
At a high level, a Transformer acts like a black box that deals with natural language. For instance, to translate a sentence we would have:
✅ Input: Spanish sentence "¿De quién es?"
✅ Processing: The model encodes the meaning
✅ Output: English translation: "Whose is it?"

Inside this black box, we find two key components:
1️⃣ The Encoder – Converts the input into a structured representation.
2️⃣ The Decoder – Transforms this representation into the final output.
2.1. The Encoder
This part takes our input and converts it into a matrix representation. For example, it processes the Spanish sentence "¿De quién es?" and transforms it into a structured format that captures the essence of the input.

2.2. The Decoder
This component receives the encoded representation and iteratively generates the output. In our case, it takes the encoded data and produces the translated sentence "Whose is it?" in English.
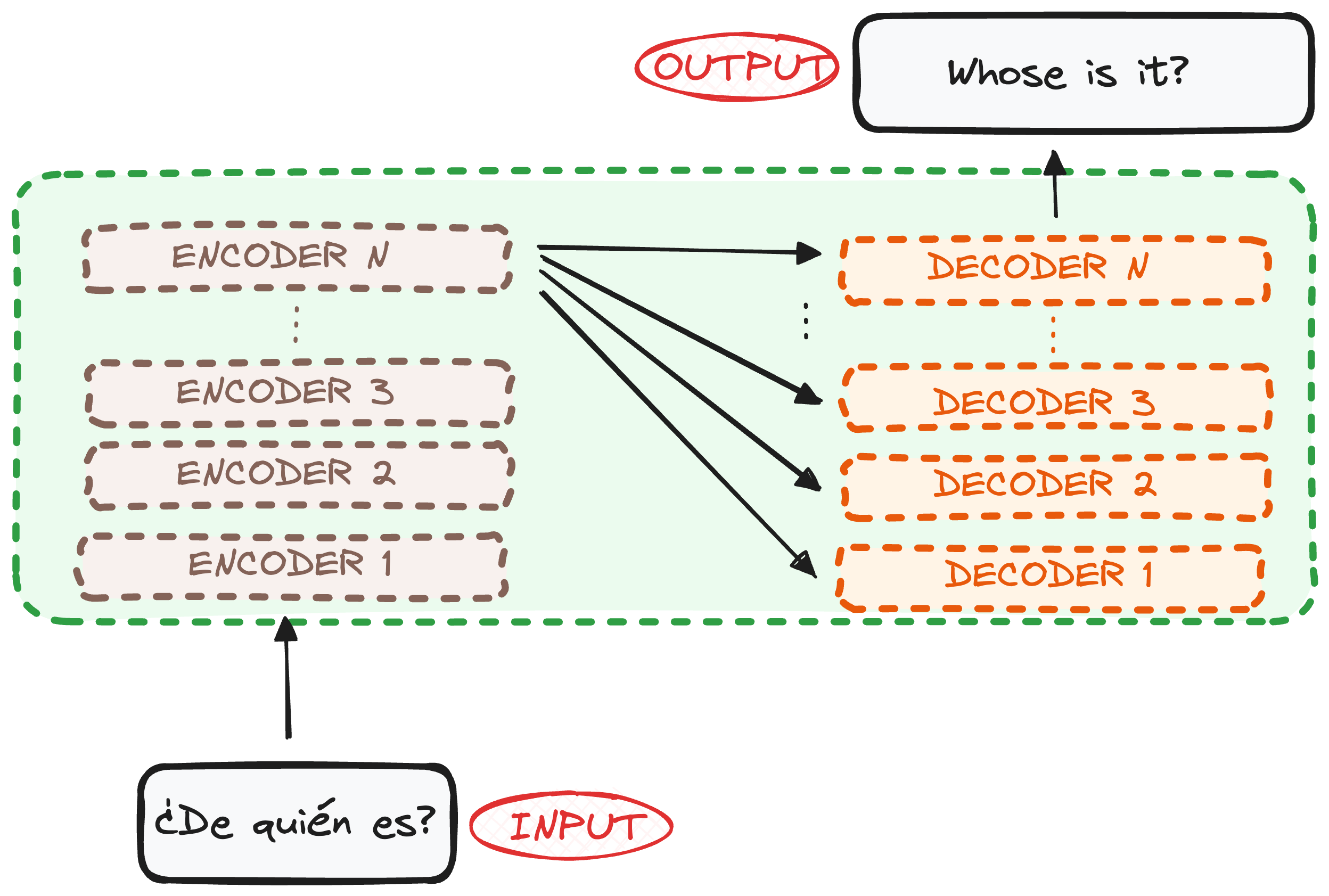
3. The Encoder-Decoder Structure 🔄
Each Transformer consists of multiple encoder and decoder layers that refine and process the data step by step.
✅ Encoders process input sequentially through multiple layers.
✅ Decoders generate the output, using both the encoded data and previous decoder layers.
The original Transformer had 6 Encoders & 6 Decoders, but this structure is flexible.
4. Why Self-Attention Matters 🤯
Instead of reading words in order, Transformers evaluate the entire sentence at once—focusing on the most relevant words.
📖 Example: "The cat sat on the mat."
🔍 The Transformer immediately understands "cat" as the subject and "mat" as the object.
This makes translation, text generation, and AI-powered chatbots possible!
The overall Transformers architecture looks something like follows 👇🏻

But no worries, we will focus on both the Encoder and the Decoder.
Next Week: The Encoder Deep Dive —so stay tuned!
Before you go, tap the 💚 button at the bottom of this email to show your support—it really helps and means a lot!
Any doubt? Let’s start a conversation! 👇🏻
Want to get more of my content? 🙋🏻♂️
Reach me on:
LinkedIn, X (Twitter), or Threads to get daily posts about Data Science.
My Medium Blog to learn more about Data Science, Machine Learning, and AI.
Just email me at rfeers@gmail.com for any inquiries or to ask for help! 🤓
Remember now that DataBites has an official X (Twitter) account and LinkedIn page. Follow us there to stay updated and help spread the word! 🙌🏻
Optimus Prime eëeerreraaæ
Great post! You struck a good balance between clear technical explanations and useful illustrations